Next: The Profiler Changes Up: Introduction Previous: User Visible Changes Contents
GCC uses two different intermediate languages to represent the compiled functions. In early compilation stages abstract syntax trees (in future referred simply as ``trees'') are built as the result of parsing source code. Once whole function body is parsed, or in an old-fashioned front-end at statement basis4.1, it is lowered to the very low level register transfer language (RTL) representation, where currently the majority of optimizations is done.
The trees represent program behavior very closely to the source form, for instance C ternary operator ? do have different representation from if construct or for loop different from while. Trees are also partly front-end specific (each front-end extends the original C implementation by new nodes) making writing optimizers on this representation difficult.
Earlier mentioned AST-branch has been created to update front-ends to lower representation to common SIMPLE tree form and perform optimizations. We hope this effort will eventually result in high level optimizers for GCC -- inter-procedural optimizer, memory hierarchy loop transformation etc., but currently the code is in preliminary design stages and our decision was not to interfere our efforts with AST-branch.
RTL is the low level language used to represent program in later stages of compilation. It has form of gradual lowering implemented due to instruction splitting, so in the final stage, there is usually one to one mapping between RTL instructions and target instruction, however it is very low level in its highest form already as described below.
RTL is inspired by Lisp lists. It has both an internal form, made up of structures that point to other structures, and a textual form that is used in the machine descriptions and in printed debugging dumps. The textual form uses nested parentheses to indicate the pointers in the internal form.
Each instruction in RTL form is represented as a nested tree of nodes, where each node has its code specifying the semantics, mode specifying the type the node operates on and arguments. Arguments are typed and type is known from code. rtl.def contains formal description of codes and lists of their types in the string form available to the compiler. This makes it easy to traverse RTL instructions.
For instance the following example is a RTL representation of 32bit integer plus operation:
(insn UID PREV NEXT (set (reg:SI 1))
(plus:SI (reg:SI 2) (reg:SI 3)))
insn node is an container with field UID containing unique identifier of instruction and NEXT, PREV of linked list of instructions.
set node is used to represent stores to the first operand (pseudo register 1) and the second operand is the actual expression. SI is mode representing 32bit integer (Single Integer).
RTL semantics is target independent making it possible to write common optimizers for all targets, however the syntax (set of allowed instructions) is target dependent. For instance i386 back-end describes conditional jump as:
(insn 56 13 57 (set (reg:CCGC 17 flags)
(compare:CCGC (reg:SI 61)
(reg:SI 62))))
(jump_insn 57 56 33 (set (pc)
(if_then_else (ge (reg:CCGC 17 flags)
(const_int 0))
(label_ref 22)
(pc))))
Closely describing the presence of flags register (register 17) on i386 architecture and split between compare and conditional jumps. Even the fact that compare instruction is not required to set carry flag is described by presence of CCGC mode. Same comparison on Alpha architecture looks different:
(insn 54 52 55 (set (reg:DI 80)
(lt:DI (reg:DI 78)
(reg:DI 79))))
(jump_insn 55 54 28 (set (pc)
(if_then_else (eq (reg:DI 80)
(const_int 0))
(label_ref 17)
(pc))))
Representing the fact that Alpha does not have 32bit operations, and everything is done in 64bit (DI stands for Double Integer) and that general purpose registers are used to hold predicates for conditional jumps.
This close representation of instructions allows GCC to do lots of target specific optimizations (such as in i386 case use single comparison for multiple jump or conditional move instructions), and allows easy re-targeting of GCC without complicated peephole pass, but it brings difficulties to higher level optimizers, as analyzing RTL in few dozen possible forms is difficult. This explains the motivation for mid-level RTL, where for instance all conditionals do have the common form:
(jump_insn 14 13 33 (set (pc)
(if_then_else (ge (reg:SI 61)
(reg:SI 62))
(label_ref 22)
(pc))))
Full description of RTL and tree languages is present in [1].
A control flow graph (CFG) is a data structure built on top of the intermediate code representation (RTL instruction chain or trees) abstracting the control flow behavior of compiled function. It is an oriented graph where nodes are basic blocks (chains of instructions allways executed in sequence) and edges represent possible control flows from one basic block to another.
GCC had multiple implementations of CFG in various optimization passes. For our project we needed to unify all representations and decided to base our work on the most modern one, implemented in 1997 by Richard Henderson for the liveness analysis and register allocator update.
Unlike the other implementations usually designed as arrays of basic blocks and bitmaps of edges, Richards implementation used linked lists to represent edges allowing us to modify CFG easily.
Full description of the CFG representation and overview of routines that we
developed to maintain it easily is present in chapter ![[*]](crossref.png) that we have submitted
for inclusion into official GCC manual.
that we have submitted
for inclusion into official GCC manual.
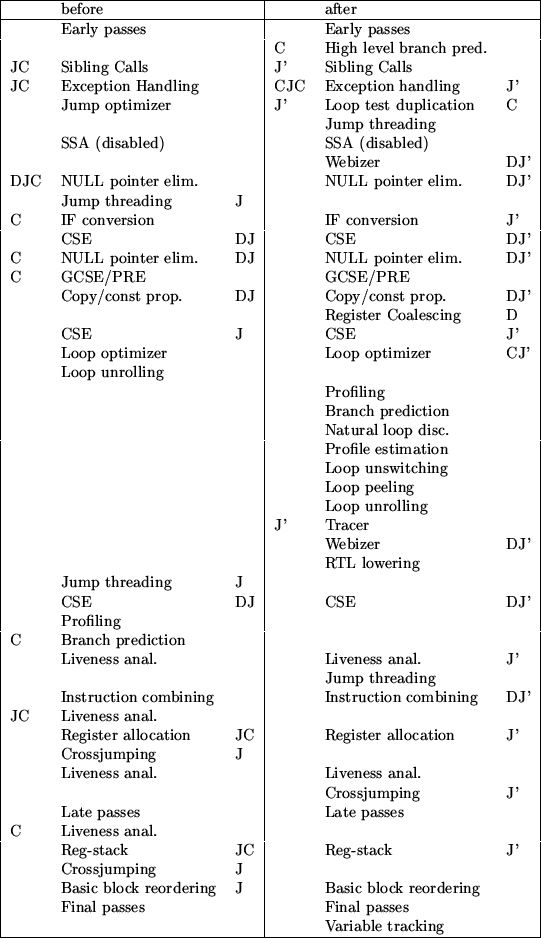
. CSE refers to common subexpression elimination pass, GCSE/PRE
refers to global4.2 partial redundancy elimination pass, SSA refers to single
static assignment form based optimizations, that are unfortunately not working
in GCC at the moment.
For compactness the common cleanup passes run before or after pass, if enabled, are referred by letters. `C' stands for CFG rebuild, `J' stands for jump optimizer, `J'' stands for our new CFG-cleanup pass replacing jump optimizer, `D' stands for trivially dead instruction removal.
As one can easily see, we have dramatically reduced amount of CFG rebuilds. Our new jump optimizer implementation is faster, CFG and life info transparent which makes it possible to be run more times resulting in better code and less interference between optimization passes making development easier.
With tracer disabled, resulting compiler is faster than before, as CFG-cleanup overall consumes less time than old jump optimizer, liveness information is recomputed fewer times, as CFG is rebuilt. With tracer enabled, compiler is slower, since tracer performns lots of duplication and several optimization passes are run on more instructions than previously.
For description of individual passes, we shall refer reader to GCC manual [1]
and chapter .
Jan Hubicka 2003-05-04