Next: Implemented Optimizations Up: Porting GCC to the Previous: AMD64 Instruction Set Overview
Since GCC has been one of the first compilers ported to the platform, we had a chance to design the processor specific part of the application binary interface [AMD64-PSABI] from scratch. In this section we discuss the decisions we made and rationale behind them. We also discuss the GCC implementation, as well as problems we encountered while porting the software.
Majority of [AMD64-PSABI] has been designed in the early stages of development with just preliminary implementation of AMD64 support in GCC and no hardware nor simulator available. Thus we had just limited possibilities for experiments and most of our decisions has been verified by measuring of executable files sizes and number of instructions in them.
We never made serious study on how these relate to the performance, but it may be expected that the relation is pretty direct in the cases we were interested in.
We do use 64-bit pointers and long. The type int is 32-bit. This scheme is known as LP64 model and is used by all 64-bit UNIX ports we are aware of.
64-bit pointers bring expansion of the data-structures and increase memory
consumption of the applications. A number of 64-bit UNIX ports also specify
a code model with 32-bit pointers, LP32. Because of large maintenance cost of
extra model (change of pointer size requires kernel emulation layer and brings
further difficulties) and because of support for native 32-bit applications we
decided to concentrate on LP64 support first and implement LP32 later only if
necessary. See also Section ![[*]](crossref.png) for some further discussion.
for some further discussion.
We considered the long long type to be 128-bit, since AMD64 has limited support for 128-bit arithmetics (that comes from extending support for 32-bit arithmetic in 16-bit 8086), however there are many programs that do expect long long to be exactly 64-bit, thus we specify optional __int128 instead. At the moment no library functions to deal with the type are specified so it's usage in C environment may be uncomfortable. This is something we may consider to address in future extension of the ABI document.
The size of long double is 128 bits with only first 80 bits used to match native x87 format. The rest is just padding to keep long double values 128-bit aligned so loads and stores are effective. The padding is undefined that may bring problems when one is using memcmp to test for equality of two long double values.
Additionally we specify __m64 and __m128 types for SIMD operations.
All types do have natural alignment. ([i386-ABI] limits the alignment to 32-bit that brings serve performance problems when dealing with double, long double, __m64 and __m128 types on modern CPU.) It is allowed to access misaligned data of all types with the exception of __m128, since CPU traps on misaligned 128-bit memory accesses.
Our GCC implementation does support all specified types with the exception of __float128. At the moment GCC is not ready to support two extended floating point formats having the same size and thus implementing it would require considerable effort.
The 128-bit arithmetics patterns are also not implemented yet so code generated for __int128 is suboptimal.
Unlike [i386-ABI] we do not enforce any specific organization of stack frames giving compiler maximal freedom to optimize function prologues and epilogues. In order to allow easy spilling of x87 and SSE registers we do specify 128-bit stack alignment at the function call boundary, thus function calls may need to be padded by one extra push since AMD64 instruction set naturally aligns stack to 64-bit boundary only.
We additionally specify the red zone of 128 bytes below the stack pointer function can use freely to save data without allocating the stack frame as long as the data are not required to survive function call.
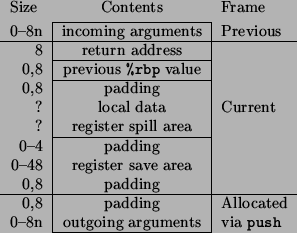
The sample stack frame organization based on extending the usual IA-32 coding practice to 64-bit is shown at Figure 1, the sample prologue code is shown at
Figure 2.
We found the use of frame pointer and push/pop instructions to be common bottleneck for the function call performance. The AMD Opteron CPU can execute stores at the rate of two per cycle, while it requires 2 cycles to compute new %rsp value in push and pop operations so the sequence of push and pop operations executes 4 times slower.
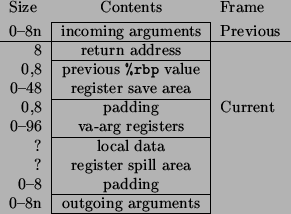
We reorganized the stack frame layout to allow shorter dependency chains in the prologues and epilogues as shown on Figure 3.
To save and restore registers we commonly use the sequence of mov instructions and we do allocate whole stack frame, including outgoing argument area, using single sub opcode as shown in Figure 4. AMD Opteron processor executes the prologue in 2 cycles, while the usual prologue (Figure 2) requires 9 cycles. Similarly for the epilogues.Unfortunately the produced code is considerably longer -- the size of push instruction is 1 byte (2 bytes for extended register), while the size of mov is at least 5 bytes. In order to reduce the expenses, GCC does use profile information to use short sequences in the cold function. Additionally it estimates number of instructions executed per one invocation of function and use slow prologues and epilogues when it exceeds given threshold (20 instructions for each saved register).
We found heuristics choosing between fast and short prologues difficult to tune
-- the prologue/epilogue size is most expensive for small functions where it
also should be as fast as possible. As can be seen in the Table
, the described behavior results in about 1% speedup
at the 1.1% code size growth (``prologues using moves'' benchmark). Bypassing the heuristics and using
moves for all prologues results in additional speedup of 1% and additional
1.1% code size growth (``all prologues using moves'' benchmark). The
heuristics works better with profile feedback (Table
). This is something we should revisit in the
future.
GCC does always eliminate the frame pointer unless function contain dynamic stack allocation such as alloca call. This always result in one extra general purpose register available and fewer instructions executed.
Contrary to the instruction counts, eliminating of frame pointer may result in larger code, because %rsp relative addressing encoding is one byte longer than %rbp relative one. Thus it may be profitable to not eliminate frame pointer when function do contain many references to the stack frame. Command line option -fno-omit-frame-pointer can be used to force use of frame pointer in all functions.
For 64-bit code generation omitting frame pointer results in both smaller and
faster code on the average (Tables ,
, and
). In the contrary, for 32-bit code generation it
results in code size growth (Tables and
). This is caused by the fact that increased
register file and register argument passing conventions eliminated vast majority of
stack frame accesses produced by the 32-bit compiler.
In GCC stack frame layout the register save area and local data are reordered to reduce number of instruction when push instructions are used to save registers -- the stack frame and outgoing arguments area allocation/deallocation can be done at once using single sub/add instruction. The disadvantage is that leave can not be used to deallocate stack frame in combination with push and pop instructions. In our benchmarks the new approach brought noticeable speedups for 32-bit code, however it is difficult to repeat the benchmarks since the prologue/epilogue code is dependent on the new stack frame organization and would require some deeper changes to work in the original scheme again.
At the moment GCC is just partly taking advantage of the red zone. We do use red zone for leaf functions having data small enough to fit in it and for saving some temporarily allocated data in instruction generation (so the sub and add instructions in Figure 4 would be eliminated for leaf functions). For the benefit of kernel programming (signal handlers must take into account the red zone increasing stack size requirements), option -fno-red-zone is available to disable usage of red zone entirely.
As can be seen in the Tables and
, red zone results in slight
code size decrease and speedups. The effect depends on how many leaf functions
require stack frame. This is uncommon for C programs, but it happens more
frequently in template heavy C++ code where function bodies are large due to
in-lining (Tables and ).
We do not use the red zone for spilling registers nor for storing local variables in non-leaf functions as GCC is not able to distinguish between data surviving function calls and data that does not. Extending GCC to support it may be interesting project and may reduce stack usage of programs, however we have no data on how effective the change can be.
To further reduce the expenses, GCC does schedule the prologue and epilogue sequence to overlap with function body. In the future we also plan to implement shrink-wrapping optimization as the expense of saving up to 6 registers may be considerable.
To allow stack unwinding, we do use additional information saved in the same format as specified by DWARF debugging information format [DWARF2]. Instead of .debug_frame section specified by DWARF we do use .eh_frame section so the data are not stripped.
The DWARF debugging format defines unwinding using the interpreted stack machine describing algorithms to restore individual registers and stack frames. This mechanism is very generic and allows compiler to do pretty much any optimization on stack layout it is interested in. In particular we may eliminate stack frame pointer and schedule prologues and epilogues into the function body.
The disadvantage is the size of produced information and speed of stack unwinding.
Implementation in GCC was straightforward as DWARF unwinding was already used for exception handling on all targets except for IA-64. We extended it by support for emitting unwind info accurate at each instruction boundary (by default GCC optimize the unwind table in a way so it is accurate only in the places where exceptions may occur). This behavior is controlled via -fasynchronous-unwind-tables.
GCC perform several optimizations on the unwind table size and the tables are additionally shortened by assembler, but still the unwind table accounts for important portion of image file size.
As can be seen in the Table
it consumes, at the average, 7.7% of the stripped program binaries size, so
use of -fno-asynchronous-unwind-tables is recommended for program
where unwinding will never be necessary.
The GCC unwind tables are carefully generated to avoid any runtime resolved relocations to be produced, so with the page demand loading tables are never load into memory when they are not used and consume the disc space only.
Main problem are the assembly language functions. At the present programmer is required to manually write DWARF byte-code for any function saving register or having nonempty stack frame in order to make unwinding work. This is difficult and most of assembly language programmers are unfamiliar with DWARF. It appears to be necessary to extend the assembler to support describing of the unwind information using the pseudo-instructions similar to approach used by [IA-64-ABI].
The decision on split in between volatile (caller saved) and non-volatile (callee saved) register presented quite difficult problem. The AMD64 architecture have only 15 general purpose registers and 8 of them (so called extended registers) require REX prefix increasing instruction size. Additionally the registers %rax, %rdx, %rcx, %rsi and %rdi implicitly used by several IA-32 instructions. We decided to make all of these registers volatile to avoid need to save particular register only because it is required by the operation. This leaves us with only %rbx, %rbp and the extended registers available for non-volatile registers. Several tests has shown smallest code to be produced with 6 global registers (%rbx, %rbp, %r12-%r15).
Originally we intended to use 6 volatile SSE registers, however saving of the registers is difficult: the registers are 128-bit wide and usually only first 64-bits are used to hold value, so saving registers in the caller is more expensive.
We decided to delay the decision until hardware is available and run several benchmarks with different amount of global registers. We also experimented with the idea of saving only lower half of the registers. Our experiments always did lead to both longer and slower code, so in the final version of ABI all SSE registers are volatile.
Finally the x87 registers must be volatile because of their stack organization and the direction flag is defined to be clear.
To pass argument and return values, the registers are used where possible. Registers %rdi, %rsi, %rdx, %rcx, %r8 and %r9 are used to pass integer arguments. In particular, register %rax is not used because it is often required as special purpose register by IA-32 instructions so it is inappropriate to hold function arguments that are often required to be kept in the register for a long time. Registers %xmm0-%xmm5 are used to pass floating point arguments. x87 registers are never used to pass argument to avoid need to save them in variadic functions.
To return values registers %rax, %rdx, %xmm0, %xmm1, %st0 and %st1 are used. The usage of %rax for return value seems to be considerable win even at the expense of extra mov instruction needed for functions returning copy of the first argument and functions returning aggregates in memory via invisible reference.
The aggregates (structures and unions) smaller than 16 bytes are passed in registers. The decision on what register class (SSE, integer or x87) to use to pass/return the aggregate is rather complicated; we do pass each 64-bit part of structure in separate register, with the exception of __m128 and long double.
The argument passing algorithm classifies each field of the structure or union recursively into one of the register classes and then merge the classes that belongs to the same 64-bit part. The merging is done in a way so integer class is preferred when both integer and SSE is used and structure is forced to be passed in memory when difficult to resolve conflicts appears. The aggregate passing specification is probably the most complex part of the ABI and we hope that the benefits will outweight the implementation difficulties. For GCC it requires roughly 250 lines of C code to implement.
Arguments requiring multiple registers are passed in registers only when there are enough available registers to pass argument as a whole in order to simply va_arg macro implementation.
Variable sized arguments (available in GCC only as GNU extension) are passed by reference and everything else (including aggregates) is passed by value.
It is difficult to obtain precise numbers, but it is clear that the register passing convention is one of the most important changes we made relative to [i386-ABI] improving both performance and code size. The amount of stack manipulation is also greatly reduced resulting in shorter debug information. On the other hand, the most complex part, passing of aggregates, has just minor effect on C code. We believe it will become more important in future for C++ code.
At the moment GCC does generate suboptimal code in number of cases where aggregate is passed in the multiple registers -- the aggregate is often offload to memory in order to load it into proper registers. Beside that GCC should implement all nuances of argument passing correctly.
For functions passing arguments in memory, the stack space is allocated in
prologue; deallocated in epilogue and plain mov operations are used to
store arguments. This is in contrast to common practice to use push
operation for argument passing to reduce code size. Despite that experimental
results shows both speedups and code size reductions of the AMD64 binaries
when mov instructions are used (See -maccumulate-outgoing-args in
the Table ,
, ,
and ). This is in sharp contrast to IA-32 code generation
experience (Tables and
).
There are multiple reasons for the image size to be reduced. Usage of push instructions increases unwind table sizes (about 3% of the binary size). Most of the functions has no stack arguments, however they still do require stack frame to be aligned. This makes GCC to emit number of unnecessary stack adjustments. Last reason seems to be fact that majority of values passed on the stack are large structures where GCC is not using push instructions at all.
More complex argument passing conventions require nontrivial implementation variable argument lists. The va_list is defined as follows:
typedef struct {
unsigned int gp_offset;
unsigned int fp_offset;
void *overflow_arg_area;
void *reg_save_area;
} va_list[1];
The overflow_arg_area points to the end of incoming arguments area.
Field reg_save_area points to the start of register save area.
Prologue of function then uses 6 integer moves and 6 SSE moves to save argument registers. In order to avoid lazy initialization of SSE unit in the integer only programs, hidden argument in the register %al is passed to functions that may use variable argument lists specifying amount of SSE registers actually used to pass arguments.
We decided to use the array containing structure for va_list type same way as [PPC-ABI] do to reduce expenses of passing va_list to the functions -- arrays are passed by reference, while structures by value. This is valid according to the C standard, but brings unexpected behavior in the following function:
#include <stdarg.h>
void t (va_list *);
void q (va_list a)
{
t(&a);
}
The function t expects address of the first element in the array, while in
the second one, the array argument is merely an shortcut for a pointer so it
passes pointer to the pointer to the first argument. This unexpected behavior
did not trigger in Open Source programs since these already has been cleaned up
to work on Power-PC, but has been hit by proprietary software vendors who
claimed this to be a compiler bug even when GCC correctly emit an warning
message ``passing arg 1 of `t' from incompatible pointer type''
The computed jump is used in the prologue to save only registers needed. This results in small savings for programs calling variadic function with floating point operands, but makes program calling variadic functions using non-variadic prototypes to crash. Such programs are not standard conforming, but they happen in practice. We noticed the problem for strace and Objective C runtime. We may consider replacing the jump table by single conditional to avoid such crashes.
Second important compatibility problems arrises from implicit type promoting. All 64-bit targets supported by SuSE Linux do promote operands to 64-bit values and several packages depend on it. Most notable example is GNOME. While promoting all function operands to 64-bit would be too expensive, we may consider promoting the operands of variadic functions to avoid such compatibility issues.
The 32-bit sign extended immediates and zero extending loads of the immediate
allows convenient addressing of only first ![]() bytes of the address space.
The other areas needs to be addressed via movabs instructions or instruction pointer relative addressing. In order
to allow efficient code generation for programs that do fit in this limitation
(almost all programs today) we define several code models:
bytes of the address space.
The other areas needs to be addressed via movabs instructions or instruction pointer relative addressing. In order
to allow efficient code generation for programs that do fit in this limitation
(almost all programs today) we define several code models:
,
, and
). These penalties are larger than the authors
expectations and probably further improvements to the GCC code generation are
possible.
The position independent code generation can be effectively implemented using the instruction pointer relative addressing. We implemented scheme almost identical to IA-32 position independent code generation practices only replacing the relocations to option global offset table address and index in it by single instruction pointer relative relocation. Similarly the instruction pointer relative addressing is used to access static data.
The resulting code relies on the overall size of the binary to be smaller than
![]() bytes. An [AMD64-PSABI] extension will be needed in the case this
limitation will become a problem. The performance penalty of -fpic is
about 6% on AMD64 compared to 20% on IA-32 (see Tables
, ,
and ).
bytes. An [AMD64-PSABI] extension will be needed in the case this
limitation will become a problem. The performance penalty of -fpic is
about 6% on AMD64 compared to 20% on IA-32 (see Tables
, ,
and ).
Jan Hubicka 2003-05-04